Theses at the Royal Academy of Arts, The Hague
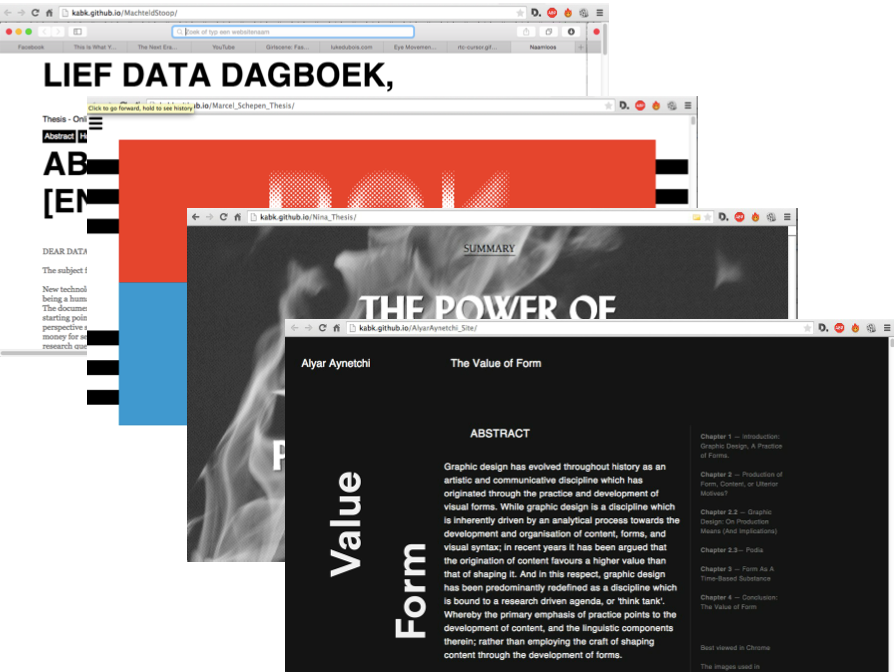
The Royal Academy of Arts in The Hague, The Netherlands runs a well-known Graphic Design Bachelor program. In recent years head teachers Roosje Klap and Niels Schrader have reinvigorated the program with a focus on social responsibility and the appropriation of digital technologies. Each year in the four-year program features as a subject both Coding and Interaction Design.
The Bachelor thesis has been an important part of the curriculum for many years. It allows the student to research into a specific area of interest and will provide a theoretical foundation for their final exam project. The theses have traditionally had a final output form of a printed publication: these are archived in the school libraries. With the curriculum placing more importance on digital design, the nature of the thesis is open to be re-imagined.
The class of 2015 are the first to create a version of their thesis designed for the screen. These theses are gathered online, and also available through the website presenting the students graduation projects, whileyouweresleepingkabk.com. This article details the workflow chosen to create these digital theses.
Life after the template
The form of the thesis in art education is distinct from the papers written at Universities, especially seen in relation to the role of the template. The challenge has been to come up with a workflow for creating digital theses that gives the students the needed flexibility to express their ideas both in writing and design.
Requirements
Starting in the academic year 2014/2015 we ask students to create their thesis for the screen. More specifically, we presented the students not with a screen-only model, but a screen-centric model. The students are free to create a print version of their thesis, but are encouraged to take the version conceived for the screen as the departure point.
Scientific publications often choose a pre-formatted form. Magazines will provide templates to follow for authors, that in most cases use Microsoft Word or the LaTex authoring system. The first texts to be shared online were academic papers, and the separation of form and content that is habitual in academic publishing has permeated every aspect of the online publishing eco-system. In contrast, the students in The Hague are are expected to engage in the design of their thesis. Form and content are decidedly mixed. Clearly, the last thing we want to do is give the students a template.
There are additional requirements. With a group of 50 students, we need to be able to follow the process of all students, be able to give feedback. Also, we are legally required to archive all theses. Finally, we want to publish the theses online in an accessible and durable way.
The paradox of choice
The landscape of web technology is varied and ever changing. Creating an advanced web project might include choosing a server side programming language (Python, PHP, Node.js) that talks to a database of choice, then creating the visual and interaction design on top of a foundation of front-end ‘frameworks’ and ‘pre-processors’.
The amount of choices to make is staggering, and the complexities of such systems high. For the project at the KABK we have foregone these technologies, for a more simple, back to basic approach: writing HTML pages.
Writing websites like it’s 1999
The first web-sites were exactly this: ‘hand-crafted HTML’. Many small sites were created as a series of HTML pages, with occasional updates (the person designing the site might then charge for each update!). Coding was not always necessary: tools like Adobe Dreamweaver provided both a visual view and a code view.
‘The Secret History of Kubrick, the Blog Theme That Changed the Internet’
The democratisation of Content Management Systems like WordPress and Joomla have changed the equation. In these systems, a general design is encoded into a template, and the contents for individual pages are stored in a database that is easily editable by the user. For clients this saves time and money. The downside is that a Content Management System requires shoehorning every page into templates: these early HTML pages offered much more freedom in this respect, as potentially every page could be modified and changed to the designer’s whims.

The workflow proposed for the theses thus resembles the cultural moment lovingly captured by Ola Lialina and Dragan Espenschied in the publication Digital Folklore. The period in the 1990ies when large groups of enthousiasts learned and experimented with the fabric of the web, creating their own websites on such digital platforms as Geocities and in the process shaping the visual codes of the medium.
An ideal system would undoubtedly combine elements of both paradigms: easy customisation and user-friendly content management. But with the design students, we choose to re-appropriate the 1990ies approach. Here are the reasons:
- The contents and design of the thesis are supposed to be intimately related. The web standards HTML, CSS and JavaScript are the language of web design. To be able to directly edit the HTML of the pages instead of generating them through a system, gives the full control needed in this situation.
- The advantages of Content Management Systems become apparent for larger collections of texts that need to be similarly laid out. The thesis is one text, and not a very long text at that. There is little efficiency to be gained from creating a template.
- Graphic designers can be expected to know the languages of the web. At least, in the programme at the KABK they are. So even if the editing of text files is not a very accessible method for the larger public, it is perfectly acceptable for the intended audience.
Working with Github
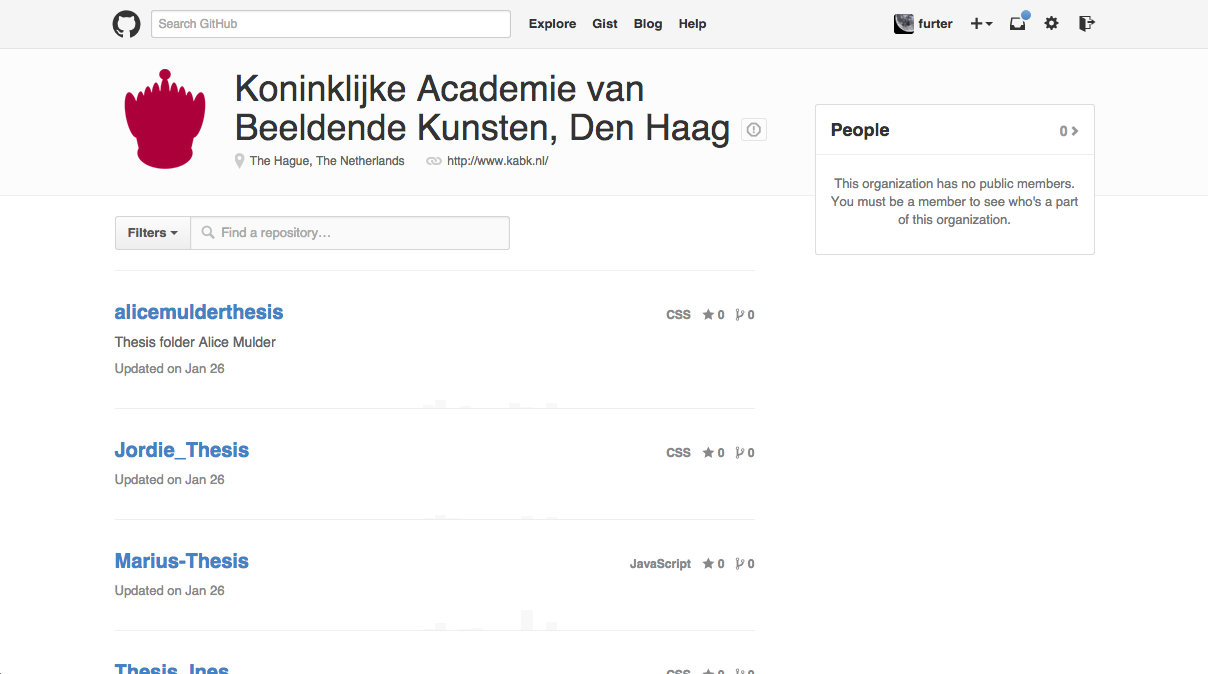
Github is code hosting site that focuses on facilitating the collaboration between developers. It is built on the Open Source software Git. Each contributor works on their own computer, on their own version of the files. They can then use Git to merge their changes with those of others.
Github also offers the possibility to publish files to the internet. This feature is usually used to publish the documentation for a code project, contained in a special branch. Our ‘hack’ was to only use this branch for the theses. The result was a very nimble workflow: each file-change uploaded to Github was immediately published online.
Most students had no prior experience with Git—getting everybody set up and comfortable with the system did take time. Doing this in the class-room made sure students could help each other out, and minimised the frustration associated with trying unknown technologies.
The setup proved extremely practical for the teachers. Having the work in progress online is very practical for the teacher, for they can simply click through links instead of having to download code. This does mean in-progress texts are publicly accessible. To mitigate this potential problem we have shown students how to hide from search engines.
Indexation, Syndication
The one major advantage of data-base driven Content Management Systems is that it is very easy to generate indexes. The same database from which a single page will be fetched, will just as happily generate a listing of pages, sorted and filtered as the designer demands. Because most CMS’s are dynamic, these indexes will be kept up to date automatically: every time the page is rendered, the indexes will be re-generated.
To create indexes from a collection of HTML files is more involved: since there is no neat database model with fields like ‘title’, ‘author’, ‘publishing date’, one will need a way to discover these metadata from the HTML. Creating indexes by hand is one option, but this is error-prone and tedious.
It becomes even more involved when the indexes themselves are part of the pages, like in the submenu of a publication that show links to other pages. If a collaborator on another page changes its title, or a new page gets added, this submenu should be updated in every page—again, tedious and error-prone.
With the theses at the KABK we decided to tackle the first problem: create indexes from a series of initially unstructured HTML files. Each thesis is contained in its own folder, and the theses are largely independent from another. We create an index page that lists all theses. We do not (yet) have any intra-thesis navigation within the theses themselves—a challenge to tackle on a subsequent project.
Turning the database inside out
To create the index, we rely on the metadata provided to social networks and search engines. As practical as the database underlying CMS’s is, it has one big problem: it is inaccessible to the outside world. This has been a concern for companies that are built upon indexing and syndicating the web: search engines like Google, and social networks like Facebook and Twitter. These companies want to be able to either index, relate and preview web pages, and they need data for that.
There has been structured metadata for almost as long as HTML exists. As always, there are conflicting standards. RDF/A, microdata and JSON-LD are now competing. We use a set of metadata that is currently recognised by search engines and social networks. The students implement this metadata in their theses. A script ‘scrapes’ all theses, analyses the metadata, and generates the index.
On the website of the end exam exhibition ‘While you were sleeping’ one can consult the presentation of the end exam of the students of the Class of 2015, and also find the links to their theses.
Conclusions
The workflow we came up with combines both new and time-tested web publishing technologies.
The students work with what is the raw material of the internet: the web standards HTML, CSS and JavaScript. The theses’ files are exchanged, archived and hosted on a very contemporary platform: code sharing website GitHub. Beyond being a place to collaborate, Github also provides us with the tools to archive the theses, and directly publish them online. Finally, we have experimented with generating indexes and a home-page from embedded meta-data.
The workflow allows for the necessary expressiveness: students are able to come up with the appropriate design for their text, unhindered by pre-existing templates. The workflow is also remarkably practical for teachers, since it allows following up on student work easily. The school benefits by having the work automatically published and archived online.
One limitation is that the indexes we created are rather rudimentary, and the theses do not link between each other. They are quite separate publications. The scenario of having one publication, with articles with independent layouts but linked navigation, is not yet catered for.
Another limitation comes on the level of tools. The tools used by the students provided little separation of concerns, as they used the text-editor editing HTML codes for everything. Passing through the text editor requires being code-literate for each task. It also requires thinking about the code while performing tasks such as writing and editing that could be more easy to perform in a WYSIWYG interface, also for those who know how to write code.
Most publications are produced by groups of people with differing roles, used to different interfaces. The workflow used at the KABK makes mainly sense for documents like the thesis, where one author is in control over all aspects of the publication from the conception to the writing to the interaction design and development. If the workflow were to accommodate a division of labour, it would also need to accommodate more interfaces then just the text editor.
Historically, the development of editing interfaces for HTML has not been spectacular. I like tight pants and hacker culture and the fear of wysiwyg suggests that the reasons for this might be cultural more than technical. Technically, HTML is a rich format, that allows to build abstractions on it. This is more so the case then oft-used alternatives like Markdown, which force a text-based approach on all collaborators. HTML allows us to imagine separate interfaces for writing, editing, coding and designing.